GPT-3
#InformeLanaspa

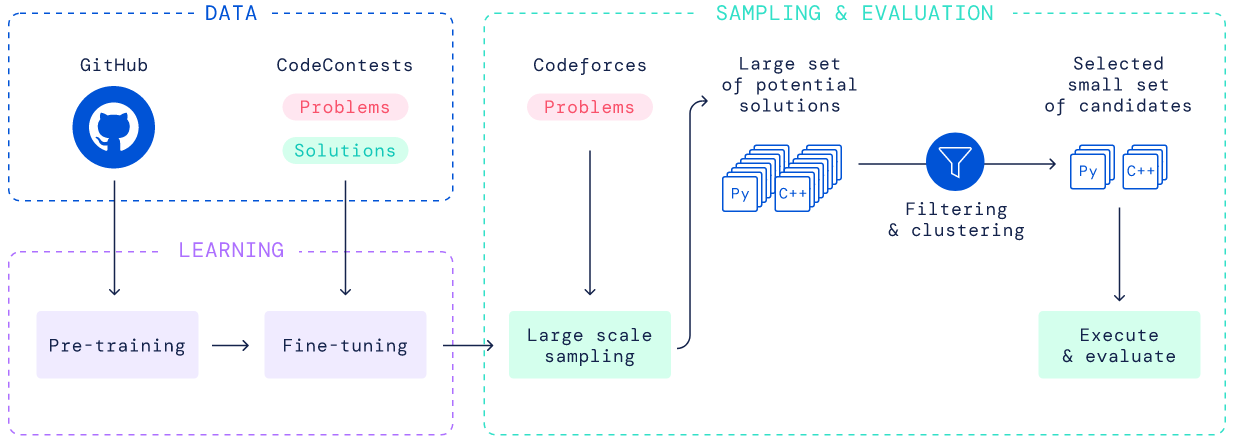
Durante las semanas pasadas se ha liberado la que parece ser la publicación científica sobre IA del año: GPT-3. GPT-3 es el modelo de lenguaje más grande jamás entrenado, dos órdenes de magnitud por encima de su antecesor GPT-2. Incluye 175B de parámetros entrenados, lo que lo hace equivalente en términos de sinapsis (enlace entre dos neuronas) al cerebro de una rata. Un gran avance aunque todavía tres órdenes de magnitud por debajo del de un ser humano.
Pero… ¿A que se viene tanto revuelo?
Un cambio de modelo
Hasta ahora el mundo del NLP trabajaba en problemas específicos que necesitaban un montón de datos particulares de entrenamiento para aprender una tarea en concreto. Un modo de trabajo muy fragmentado y de nicho que hacía que para resolver dos tareas diferentes muy probablemente se necesitasen dos arquitecturas diferentes, dos equipos separados y dos conjuntos grandes de datos totalmente diferentes.
Ahora, el mundo ha comenzado a caminar en la dirección opuesta, se ha generado un modelo “to rule them all”. Un macro modelo que se entrena una vez de manera agnóstica a cualquier problema y que es capaz de actuar con muy pocos ejemplos de contextualización ante lo que antes eran problemas muy diferenciados con soluciones muy alternas y entrenamientos muy diferenciados.
De esta manera, el mismo modelo es capaz de dar solución a todos los problemas con muy poco esfuerzo de contextualización para que el modelo entienda qué tarea tiene que resolver.
Un modelo de lenguaje en si, lo único que hace es predecir el siguiente token (una palabra, un número…) en base a los tokens previos introducidos para contextualizarlo en la tarea con una serie de ejemplos base. Entonces, ¿qué puede hacer exactamente GPT-3? ¿Y por qué esto se merece un artículo?
![[Imagen] - Ejemplos de contextualización para el modelo](https://www.planaspa.com/assets/img/posts/20200726/in-context_learning.png)
El equipo creador de OpenAI la verdad es que no ha dado muchos ejemplos de utilización a excepción de algunos que luego veremos. Sin embargo, durante el fin de semana pasado la comunidad se volcó sobre Twitter a probar el modelo y mostrar ejemplos posibles.
Tenemos personas que utilizando GPT-3 son capaces de generar código HTML para crear elementos web dándole como input lo que quieres hacer en lenguaje natural o programar en ruby porque GPT-3 fue entrenado sobre repositorios de código de Github. También tenemos ejemplos de personas que han escrito poesía, conversaciones, parodias literarias de manera automática a través de GPT-3… Para los curiosos os dejo aquí un hilo estupendo que agrega cantidad de situaciones en las que la gente está probando el modelo.
Desde luego un modelo prometedor en cuanto a versatilidad y aplicaciones que la comunidad está desarrollando. Veremos qué va surgiendo durante los próximos meses.
Resultados obtenidos
El equipo de OpenAI, a parte de generar el modelo, ha realizado unos experimentos que explica en su paper de más de 70 páginas. No vamos a hablar de todos ellos pero si quiero ahondar en dos en específico que me han resultado particularmente llamativos por el resultado arrojado.
Por un lado, han utilizado GPT-3 para generar artículos de noticias sintéticas, es decir, han generado artículos que simulasen haber sido escritos por periodistas especializados. Lo importante no es que hayan conseguido generar noticias de manera sintética, lo importante es que han realizado pruebas con usuarios en el que a un usuario le presentaban dos artículos, uno generado por GPT-3 y otro escrito por un periodista de verdad para que el usuario determinase cual era el artículo sintético.
![[Imagen] - Los usuarios no distinguen entre GPT-3 y periodistas reales](https://www.planaspa.com/assets/img/posts/20200726/articles.png)
Los resultados han sido increíbles, conforme aumentaba la complejidad del modelo (la capacidad de computación utilizada y el tiempo de entrenamiento), la tasa de aciertos de los usuarios bajaba. Al llegar al máximo de parámetros entrenados para GPT-3, 175B, los usuarios acertaban un 52% de las veces sobre cuál de los dos artículos era el generado de manera sintética.
Si un ser humano llega a no ser capaz de diferenciar una noticia escrita por un ser humano o una máquina existen muchas preguntas que nos pueden venir a la cabeza.
Pero esto no acaba aquí, segundo experimento: Aritmética. El ejercicio es simple, al modelo se le incluye como entrada una sentencia estilo “2+2=”, en el que se incluyen varios operadores y una operación a realizar para que el modelo realice la predicción del siguiente token en base a los tokens anteriores. Aquí es importante reflexionar de nuevo que el modelo no ha sido entrenado específicamente para resolver sumas, si no que ha sido entrenado con fuentes de datos genéricas como Wikipedia o Github.
Hasta ahora, con los modelos anteriores como GPT-2 el modelo no era capaz de predecir correctamente el siguiente token, sin embargo, con GPT-3 los resultados han sido muy esperanzadores. Conforme el modelo se entrenaba con más parámetros, el modelo era capaz de resolver a la perfección más operaciones, llegando a una cifra de 100% de acierto en sumas y restas de dos dígitos y porcentajes de aciertos muy buenos en sumas y restas de 3 dígitos.
![[Imagen] - Tasa de aciertos en operacioes artimeticas vs complejidad del modelo](https://www.planaspa.com/assets/img/posts/20200726/arithmetic.png)
Sin embargo, para entender la importancia de este hito, los creadores del modelo decidieron hacerse la siguiente pregunta para asegurarse que el modelo simplemente no se había aprendido esas secuencias “de memoria” durante la fase de entrenamiento: ¿Cuantas de estas operaciones estaban ya dentro del corpus sobre el que el modelo se entrenaba ? Decidieron hacer búsquedas sobre la base de datos y estos fueron los resultados:
Para la búsqueda de adiciones realizaron búsquedas que incluye el operador + y la palabra “más” (“
Además, revisando los errores del modelo en las sumas y restas, se vieron errores comunes del tipo no llevarse 1 en la suma, lo que sugiere que el modelo no estaba simplemente memorizando… ¡Si no que estaba aprendiendo a sumar solo! ¡Sin que nadie le entrenase para ello! El modelo había aprendido a aprender solo, sin que nadie le guíe.
Futuro
A todo esto hay que sumarle la línea histórica de los modelos GPT. Antes de GPT-3 existieron modelos que fueron entrenados con menos parámetros, los cuales no arrojaron tan buenos resultados pero que si que arrojaron algo importante, el modelo no parecía converger. Es decir, se entrenaban con conjuntos de datos enormes pero el algoritmo decía que aún podía aprender más, no había llegado al máximo de aprendizaje.
Por eso mismo se decidió lanzar GPT-3 un modelo órdenes de magnitud por encima de sus antecesores con el objetivo de ver converger el modelo y ver hasta dónde se podía llegar. Sin embargo, pese a los estupendos resultados de GPT-3, el modelo aún no ha convergido. Lo que quiere decir que aún le queda bastante por aprender… ¿Cuánto? Solo se sabrá cuando el modelo converja.
Para entrenar este modelo, ha costado tener un sistema con 350GB de memoria y unos 12M de dólares en pagos al proveedor de cloud para generar al modelo.
Un esfuerzo solo al alcance de grandes corporaciones, universidades o institutos de investigación. El lado positivo es que solo se necesita entrenar el modelo una vez y a partir de ese momento el modelo ya está listo para ser usado cuantas veces se quiera.
A día de hoy el modelo sigue custodiado por el equipo de OpenAI y no se entrega por completo a nadie. Para usarse se debe utilizar un API que han habilitado y a través de la cual se puede crear un modelo de negocio que daría para otro informe.
No obstante, es cuanto menos curioso pensar que este modelo no existía hacía meses y sin embargo un estudiante en cualquier parte del mundo pueda consumirlo hoy mismo a través de un API sin necesidad de gastarse 12M en generárselo el mismo. La democratización de la IA en estado puro.
Consecuencias
Todo esto da mucho que pensar y darían de si otros tantos informes, os dejo una serie de preguntas abiertas que han pasado por mi mente a raíz de toda esta investigación:
- Si no somos capaces de diferenciar entre una noticia escrita por un humano y por una máquina… ¿Podría ser utilizado este modelo como herramienta para generación masiva de noticias en una dirección política? ¿Fake news?
- La autenticación va a ser crítica en un mundo post-GPT-3, ¿podría un modelo suplantar tu manera de escribir cogiendo tus publicaciones y aprendiendo de ellas?
- Si el modelo está aprendiendo a aprender, ¿hasta dónde puede llegar esa capacidad? ¿A partir de qué momento cobra consciencia de si mismo?
- ¿Qué pasará si el modelo se sigue entrenando con aún más capacidad de computación? ¿De qué será capaz el GPT-4?
Vaticino que en unos años tendremos una competición que trate de resolver el test de Turing de la misma manera que tuvimos la competición de AlphaGo recientemente. Tiempo al tiempo.